According to Channel Advisor, a software platform for retailers, retailers lose 4% of a day's sales each hour a website is down. From H&M to Home Depot and Nordstrom Rack – all of them experienced either downtime or intermittent outages during the Holiday season of 2019. And one thing we know for sure is that there is nothing called 100% uptime. But there has to be a way to make our systems resilient and prevent outages for ecommerce sites. We at Unbxd pay the utmost attention to the growth of our customers. We ensure that they are up and running most of the time and do not suffer any business loss. And we do this by making our ecosystem robust, reliable, and resilient.
How is network resilience tested?
Resilience is the ability of the network to provide and maintain an acceptable level of service in the face of various faults and challenges to normal operation. Since the term services and recently microservices made their way into usage, application developers have converted monolithic APIs into simple and single-function microservices. However, such conversions come with the cost of ensuring consistent response times and resilience when specific dependencies become unavailable. For example, a monolithic web application that performs a retry for every call is potentially resilient, as it can recover when certain dependencies (such as databases or other services) are unavailable. This resilience comes without any additional network or code complexity. However, each invocation is costly for a service that orchestrates numerous dependencies. A failure can lead to diminished user experience and higher stress on the underlying system attempting to recover from the failure. And that is what we at Unbxd work towards - providing a seamless shopping experience for our customers across verticals.
Let us consider a typical use case where an ecommerce site is overloaded with requests on Black Friday. The vendor providing payment operations goes offline for a few seconds due to heavy traffic. The users then begin to see extended wait times for their checkouts due to the high concurrency of requests. These conditions also keep all application servers clogged with threads waiting to receive a response from the vendor. After a long wait, the result is a failure. This leads to either abandoned carts or users trying to refresh or retry their checkouts, thereby increasing the load on the application servers—which already have long-waiting threads, leading to network congestion.
This is where circuit breaker patterns can be useful!
A circuit breaker is a simple structure that constantly remains vigilant, monitoring for faults. In the scenario mentioned above, the circuit breaker identifies long waiting times among the calls to the vendor. It fails fast, returning an error response to the user instead of making the threads wait. Thus, the circuit breaker prevents users from having suboptimal response time.
This is what keeps my team excited most of the time - finding a circuit breaker pattern that is better and more efficient to form an ecosystem that can survive outages and downtimes without impact or at least with minimal impact.
Martin Fowler says, "The basic idea behind a circuit breaker is very simple. You wrap a protected function call in a circuit breaker object, which monitors for failures."
Once failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error without the protected call being made; usually, you'll also want some monitor alert if the circuit breaker trips. Recovery time is crucial for the underlying resource, and having a circuit breaker that fails fast without overloading the system ensures that the vendor can recover quickly. A circuit breaker is an always-live system keeping watch over dependency invocations. In case of a high failure rate, the circuit breaker stops calls from getting through for a small amount rather than responding with a standard error.
We at Unbxd are always working towards building the most accurate version of an Ideal Circuit Breaker. A unified system is one where we have an ideal circuit breaker, real-time monitoring, and a fast recovery variable setup, making the application genuinely resilient.

And that is what we are creating for our customers. Unbxd has many client-facing APIs. Out of the few downstream services, Catalog Service is the most important. A failure of this service implies a failure of client services as well. Failure need not always be an error, as an inability to promptly serve the request is equivalent to failure for all practical purposes. The problem for client services has been to make them resilient to this service and not bombard it if it is already down. We identified a Circuit Breaker to be an ideal solution to the problem our customers were facing. We zeroed down to Hystrix, an open-source implementation of Circuit Breaker by Netflix. All the calls to Catalog Service are wrapped in Hystrix functions. Any timeout or error downstream forces the request to be served by an alternate fallback strategy. Our team identified that the problem was building an alternate service to get us the catalog. A cache was needed to serve the purpose. This can be seen in the sequence of images below
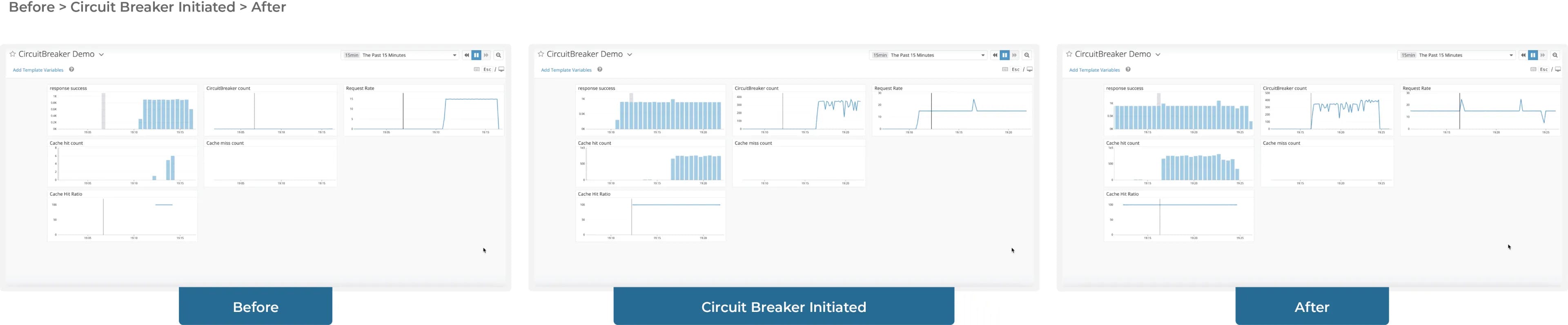
We can see that the cache hit rises as the circuit breaker gets initiated and response success is established. Once the system is restored, the cache hit decreases, and the circuit breaker is back in an open state. LRU (Least Recently Used) Cache was implemented backed by Aerospike.
LRU was chosen to go by the 80-20 rule (80% of the requests are for 20% of the products). Currently, Aerospike does not have an out-of-the-box LRU sort of implementation. To create LRU behavior, data entry/retrieval in Aerospike was made through Lua scripts that run on aerospike nodes.
Now all the successful requests are also being cached in Aerospike, and requests are served from the cache when there is a failure (either timeout or error). If the failure persists for a few seconds above a threshold percentage of the requests, the circuit becomes open so that all the requests are served from the cache only. The system keeps on actively checking for stability downstream after a sleeping window. Whenever it is stable, the circuit becomes closed, and the overall system returns to a normal state.

Using the example of the ecommerce site from above, with a resilient system in place, the circuit breaker keeps an ongoing evaluation of the faults from the payments processor. It identifies long wait times or errors from the vendor. In such occurrences, it breaks the circuit, failing fast. As a result, users are notified of the problem, and the vendor has enough time to recover. In the meantime, the circuit breaker keeps sending one request at regular intervals to evaluate if the vendor system is back online. If so, the circuit breaker closes the circuit immediately. This allows the rest of the calls to go through successfully, thereby effectively removing the problem of network congestion and long wait times. And this is how we are building a resilient system for our ecommerce customers and preventing cascading downstream failures from happening.
In the future, we aim to improve and further fine-tune our cache admission strategy. We plan to use the frequency information of an LRU to implement the same. We currently use a single successful execution to close the circuit, but we intend to use a configurable number of data points to make a more intelligent decision.
Our ideal vision is to prevent a system from any outage or possible downtime with a fully robust and resilient system in place and reduce the occurrence of any such incidents to zero.
Book a demo with Unbxd and learn how we can help reduce downtime on your eCommerce website.











