


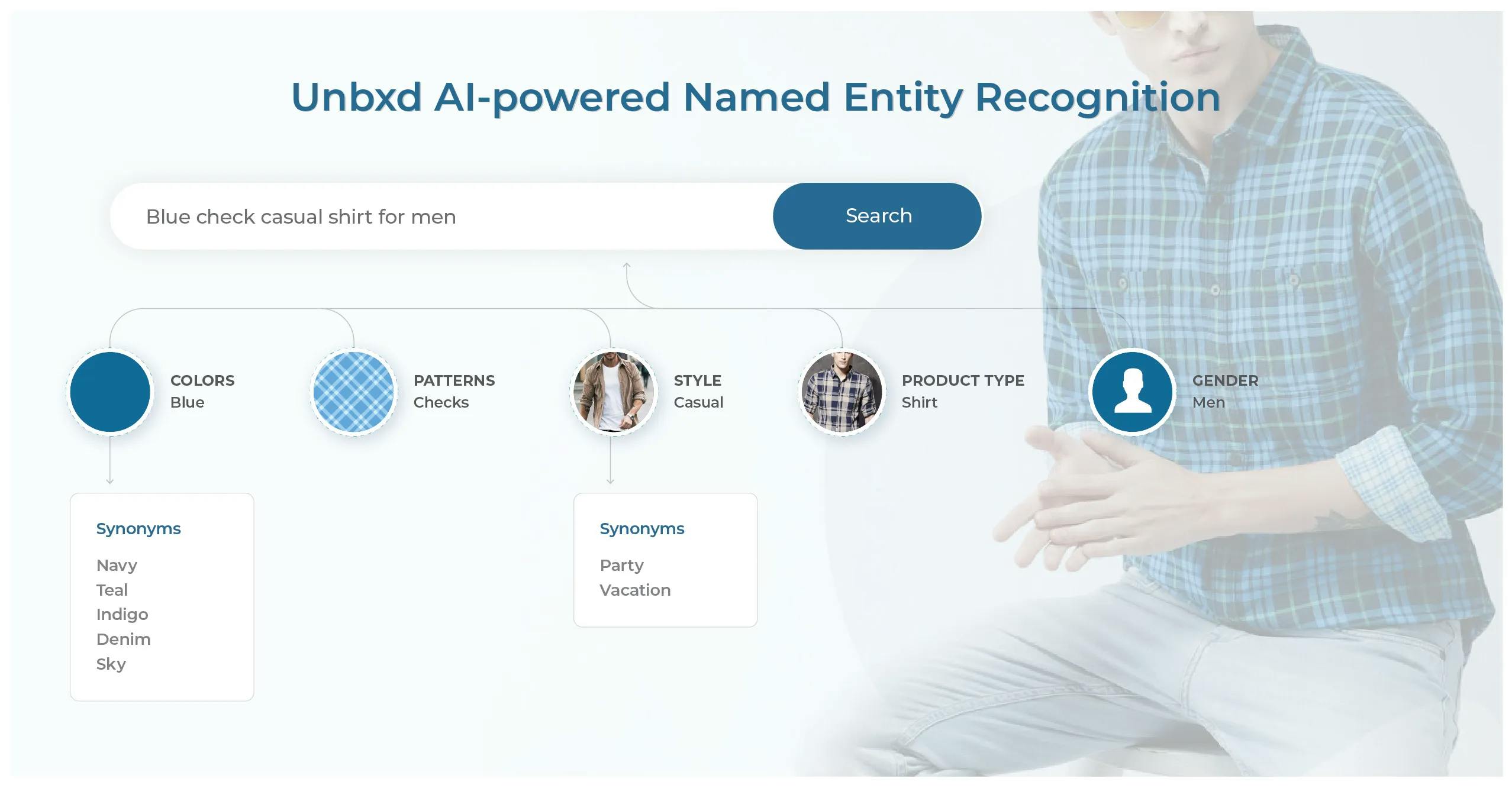
NER enables us to perform contextual query expansion, which can then be fed to our search engine for more precise and relevant results than traditional query expansion. The most common ways of query expansion include using generic synonyms, antonyms, and spell checks which apply to all the entities/attributes. One of the basic disadvantages of this approach is the expansion of ambiguous entities like a cap which can be a sleeve type for queries like cap sleeve dress and type for other queries like a cap for full sleeve dress. Query expansion without NER and entity-specific synonyms can change the meaning of the above queries.
For example, a cap sleeve dress will become (cap | cap_synonyms_fashion) (sleeve | sleeve_synonyms) (dress | dress_synonyms). However, if we were to use NER and entity-specific synonyms, it would be ( cap sleeve | cap_sleeve_sleevetype_synonyms) (dress | dress_product_type_synonyms) where cap_sleeve_sleevetype_synonyms is a synonym for cap sleeve specifically in the context of sleeve type and so on.
Without contextual query expansion, we would show results for caps along with the dress. However, with NER, we would show results in fortresses that have cap sleeves which was the user intent. The above-mentioned approach involves two important processes:
- Entity Recognition
- Query Expansion using entity synonyms
While entity extraction is not an easy problem to solve, query expansion can also be very complex. To keep things simple, we will not consider dependent entity synonyms like what should be relevant product types when the sleeve type is a cap or vice versa. There can be a lot of heuristics to do this. We can have two approaches to entity recognition:
- Simple Entity recognition models
- Joint models for Entity recognition and user intent (product type(s) or category)
Both approaches require the following data sets –
Training data
Training data for entity recognition would be a user query tagged with all its entities and user intent. For example, data for red velvet cake would be:

Needless to say, all the entities would have some score associated with them from clickstream. This score signifies the importance of each attribute for a query and, finally, for the whole data set, i.e., the customer catalog. Training data can be handcrafted or auto-generated; we prefer to go with auto-generated at our scale. The following are the sources we choose to go with:
- catalog data (product data)
- undefined
We combine clickstream and catalog data to come up with impression scores for each query, based on which we decide if the data set for that query qualifies for the training data set. The above-mentioned approach is used to generate NER tags for the historical queries of the customer. Then we generalize this understanding via a machine-learned (ML) model so that, given new queries, the model can make entity and intent predictions for various phrases in the query. NER is a natural language processing problem involving sequence-to-sequence labeling, where training data is in the following format.

The input sequence is the query terms, and the output includes the corresponding entity tags and the query intent. We learn a model such that for new input query terms, the model outputs the predicted entity tags and the query intent.
- Conditional Random Fields (CRF): CRFs are a class of statistical modeling methods that consider the context (neighboring tags) when predicting a tag. The features used to generate this are mainly the current word, next/previous words, labels of next/previous words, prefix/suffix of the words, word shapes (Digits/Alphabets, etc.), and n-gram variations of all these. While this ensures we consider the context to predict more relevant tags, it also needs enough training data set to produce good recall.
- Recurrent Neural Networks and Convolutional nets-based models: We tried out a variety of neural network-based models for sequence tagging search queries. Transition learning can be understood as a state machine approach where the input sequence passes through multiple states, and a decision is made at each state to generate the label for that state. It takes considerable training time, and the performance optimization might require good enough infrastructure, but we achieved state-of-the-art performance (> 99.9 % F1 scores) for these models. These models include the following:
- bidirectional LSTM networks (BI-Long Short Term Memory [1])
- Bi-LSTM with char CNN
- Bi-LSTM networks with a CRF layer (BILSTM-CRF)
- Bi-LSTM – CNN – CRF with the intent prediction
Each of the above models has its advantages and shortcomings; while one model might work for short queries, others may be suited for different queries. We, therefore, go with an ensemble approach that considers all the model outputs and chooses the best entities for a given query. We have built models for two types of data sets:
Domain-specific Models
Domain/vertical-specific models are where we have identified a set of common attributes/entities for that vertical. We try to fit all the queries for that vertical on it. It makes it easier for us to enable default relevance for a customer. However, there are cases where a customer could belong to a subset of a vertical or a combination of verticals; these are the cases we might not see a good performance from generic vertical-specific models.
Customer Specific Models
These datasets do not fit into a certain vertical or have uncommon attributes. A few challenges while building such models are catalog quality and getting training data for uncommon attributes.
Catalog Enrichment
Some of the customer catalogs are not very clean/structured. This is where we do catalog enrichment to include additional attributes that describe the product in a more structured manner. Catalog enrichment in itself is a very interesting and challenging problem. Once catalog enrichment is done, our NER models start performing well.
Attribute selection for recognition
We have designed our model training pipeline to capture automated feedback based on model training frequency. Models are retrained when we have good enough differential clickstream data. Since we use our NER model output to score the search results, feedback is captured in the clickstream, which is then used to retrain the models. And all of this is a continuous process. We keep running EDA and internal a/b tests to determine the accuracy and performance of our NER models. This exercise also helps us decide the training frequency of these models. We also keep adding models based on the latest enhancements in the natural language domain (and processing techniques). Significant efforts have been made towards generating contextual word embeddings (e.g., Elmo, InferSent, and BERT), which help us improve our NER models with each new version being pushed to production. You can book a demo to learn about Entity Extraction and previous accomplishments.







