


What is Vector Search?
Vector Search, a form of Semantic Search, identifies items similar to a given query by examining their similarity in vector space. Vector search represents each document or item as a vector in a multidimensional space, where each dimension corresponds to a feature or attribute of the item. The similarity between two items is calculated based on the distance between two vectors in vector space.
A significant application of vector search is often found in information retrieval and natural language processing (NLP), where it can find similar documents or items, relevant keywords, or categorize documents. It is based on the idea that items that are similar in specific ways will tend to have vectors that are close together in vector space.
Vector search has the advantage of handling large volumes of data and scaling well as the dataset size increases. In addition, it is relatively easy to implement and works with various types of data, such as text, images, and audio.
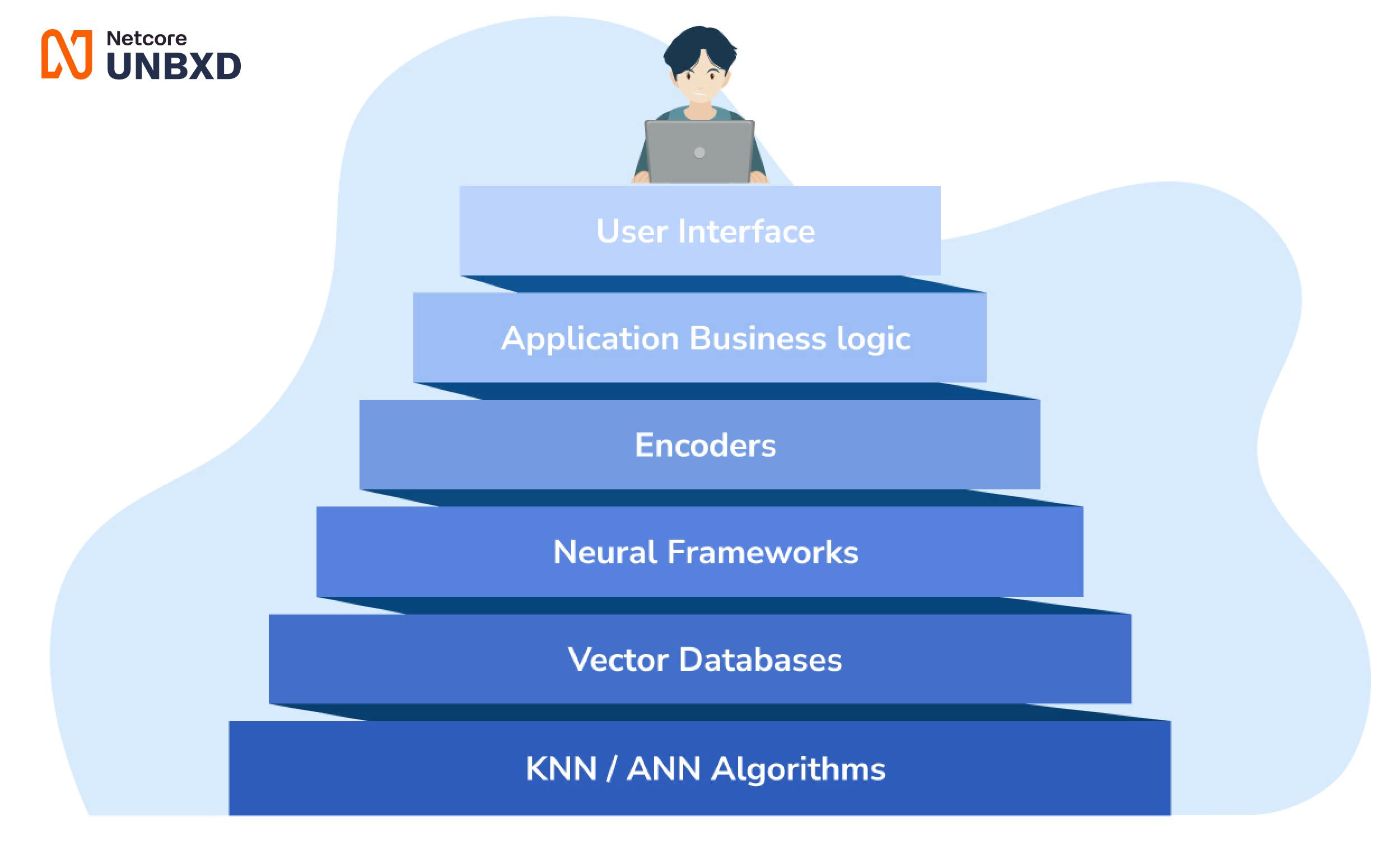
Components involved in Vector Search
Vector search typically involves the following components
- Vector Representation of Data
Data points are represented as high-dimensional vectors, where each dimension corresponds to a particular feature or attribute of the data.
- Indexing and Storage
The vectors are typically indexed and stored in Vector databases. These databases allow for the efficient retrieval of relevant vectors. Many traditional databases, like Vespa by Yahoo, are built for this purpose, launched ages ago.
- Neural Framework
Indexing and retrieving documents, made available as a software framework.
- Similarity Measure
A similarity measure is used to compare the query vector to the stored vectors in order to identify the most similar vectors. There are many Distance calculation algorithms for efficiently checking the distance between the query and a set of document vectors. For, e.g., Nearest Neighbor Algorithm
- Query processing
The query vector is processed using the same indexing and similarity calculation methods as the stored vectors in order to efficiently find the most similar vectors.
- Ranking and filtering
The retrieved vectors are typically ranked based on their similarity to the query vector and may also be filtered based on various criteria such as relevance or quality.
- User feedback
In some cases, user feedback may be incorporated into the algorithm in order to improve the search results over time.
How is Traditional (BM25) Search Different from Vector Search?
BM25 (Best Match 25) is a traditional text retrieval function often used for information retrieval and natural language processing tasks. Traditional search uses boolean retrieval to match documents from the index. It is based on the assumption that relevance is proportional to the term frequency (i.e., the number of times a term appears in a document) and inverse document frequency (i.e., the rarity of a term across the entire corpus of documents). BM25 scores are then used to rank the documents in a corpus, with the highest-scoring documents considered the most relevant.
On the other hand, vector search is based on representing documents and queries as numerical vectors in a high-dimensional space. Trey Grainger has described the core principle at work as “a word is known by the company it keeps.”
Vector-based semantic search has the capability to search not just on the term but also take into consideration the context in which the term appears. The terms in the documents are encoded into n-dimensional vectors using a transformer-encoder and then indexed into a vector indexing database. At query time, the query terms also get encoded into vectors. A nearest neighbor search is performed between the query and document vectors to fetch the most relevant documents using a distance calculation metric such as cosine similarity. The documents with vectors closest to the query vector are returned. Vector search is typically more effective than BM25 when matching semantically similar phrases and dealing with synonyms and polysemy.
Let us now take a look at how it helps us in the ecommerce industry
Long tail query
Query statistics across customer sites show that the most frequently searched terms that fall in the “head” and “mid” query category range are served well by traditional search strategies such as TF-IDF. Combined with user behavior data, they yield highly accurate results. However, when it comes to surfacing documents for less searched, “tail” and “long-tail” queries, these strategies result in decreased precision and recall. This difficulty is augmented by the fact that there’s often no user behavior data for such queries. Sometimes, the recall can go down to zero even when there are products in the catalog that match the context of the query. This is because term matching can no longer derive context from the set of words in the query. The correct results in such a scenario are semantically similar to the query, but there’s no exact match.
Netcore Unbxd would then compare this vector to the vector representations of each document in the product feed and generate results based on similarity.
NLP search
Natural language pattern search involves understanding multiple contexts in a single query and returning results closest to what the user is looking for. Here is a query from one of the prominent fashion brands in the US:
"High-waisted luxe comfort knit columnist pants."
Here, the user is talking about the pants they are looking for, which are "High-waisted." Traditional search returns one result, which isn’t the most relevant product for this query. According to our experiments, the most pertinent results are produced by vector search.
Queries containing negative keywords
Let's say a retailer is selling a "cordless circular saw," and the user is typing "circular saw without cord." First, it is important to mine the hard negatives from the query and show the relevant results. This would require a lot of work to perform using traditional frequency-based search engines.
Question and answer search
These are typical queries that would be much more relevant when there is a blog search or search for an education platform. Google’s Talk To Books is one example of how they have answered the question via the book's data.
Multi-language Search
Vector search allows text in different languages to be represented as vectors in a common high-dimensional space so that vectors represent similar meanings regardless of language. When a user enters a query in one language, we can return results to the user based on the query's mapping to the vector generated above. This may provide a more accurate and comprehensive search experience.
A world beyond semantic search
A world beyond semantic search would involve using more advanced techniques and technologies to understand and process text data. This could include:
- Deep learning techniques such as Recurrent Neural Networks (RNNs) and transformer models to better understand the context and meaning of text data.
- Knowledge graphs - a representation of data in the form of entities and relationships, which can be used better to understand the meaning and context of text data.
- Semantic Role Labeling (SRL) is a technique used to identify the roles and relationships between words in a sentence, which can be used better to understand the meaning and context of text data.
- Multi-modal search - a search that can process multiple types of data, such as text, images, and audio, to provide more accurate and relevant results.
Personalization and adaptation - a search that can adapt to the user’s needs and preferences, providing more accurate and relevant results.
These advanced techniques and technologies enable a more accurate and complete understanding of text data, which leads to more accurate and relevant search results and a better user experience.
Vector search is a powerful and versatile technique for information retrieval and natural language processing. With its ability to handle large volumes of data and scale well, it's no surprise that many companies are investing in this area. However, it's important to note that vector search is not a one-size-fits-all solution and may not be the best option for every use case. Before investing in vector search, evaluating whether it aligns with your business needs and if the benefits outweigh the costs is essential. With the ongoing research and advancements in the field, the future of vector search is promising and holds great potential for organizations looking to improve their search capabilities.








