


Stages of an AI/ML model Llfecycle
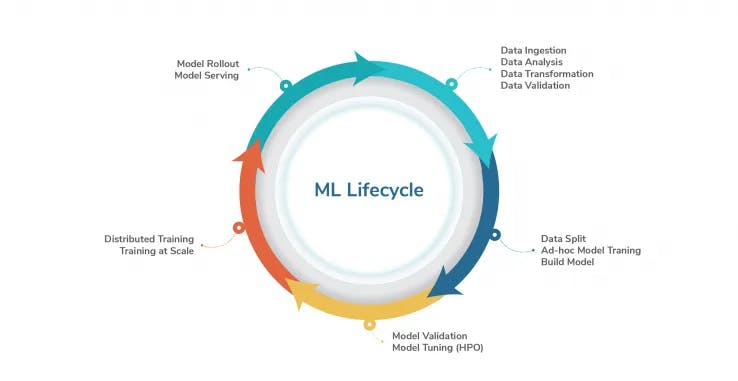
There are various stages of building an AI model:
- Data Transformations/Preparation
- Model Training
- Model Tuning
- Model Validation
- Model Serving
These stages, in fact, represent steps in an AI workflow. There are multiple open-source ML toolkits available to build an AI pipeline/workflow.
At Unbxd, we have built AI pipelines using Kubeflow to manage the model life cycle of an AI/ML model. Kubeflow comes up with almost all the ML toolkits needed to train, tune and deploy desired machine learning. Since the whole infrastructure is built on top of Kubernetes, we can use its various features like auto-scaling, rollouts, rollbacks, load balancing, etc., to support AI models at scale.
Building AI workflows and theirorchestration
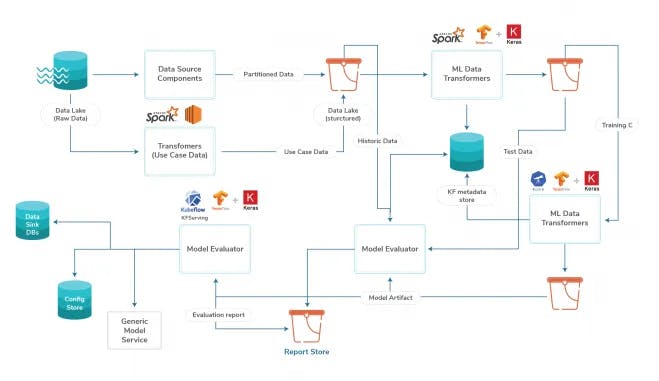
AI Pipelines are built using a combination of data transformation and machine learning components.
Data storage and transformations
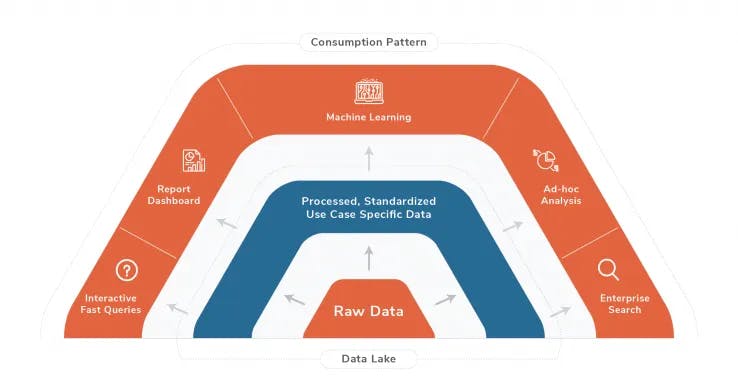
The foundation of any good AI/ML model is data. There are mainly two types of data requirements when building/serving a model; real-time data and historical data.
Historical data is the data that is needed to create an initial model artifact and model analysis. However, real-time/streaming datasets are usually needed for model serving.
Historical data is usually powered by a data lake or data warehouse based on requirements. We have opted for a data lake built on top of an object store S3 and columnar data format parquet.
Common data sources like catalog, clickstream, search API usage, etc., are partitioned by custom id to optimize customer-specific data transformations. These datasets are generated by running spark jobs on top of raw data in the data lake. We also generate many use case datasets like query-product stats, relevant user impressions, etc., to speed up data analysis and model generation pipeline.
One of the major advantages of such a data storage layer is that it helps us quickly perform selective data transformations like query stats and product stats on selective event types (click/cart/order).
We perform all data transformation tasks on standalone spark or spark on Kubernetes, depending on the use case.
Real-time data is powered by a feature store kept in sync by the analytics pipeline or catalog ingestion pipeline, depending on the data source.
Model training & tuning
Model training components are responsible for generating the model artifact. These components use TensorFlow/PyTorch/Theano/Spark ML libraries based on the model.
Distributed model training and HPO
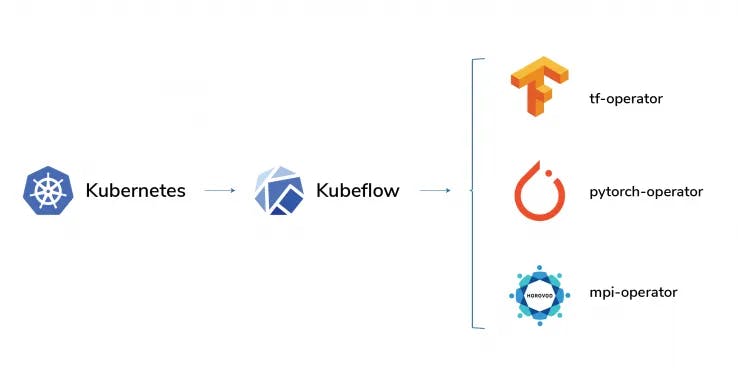
One of the major problems in model training is the enormous time taken when the dataset is huge or model architecture is complex. We usually go for bigger GPU instances, and even model training can take hours, if not days. Some of the commonly used ML frameworks (TensorFlow, PyTorch, Horovod) introduced distributed training to solve this problem. Here we make use of multiple instances to distribute the dataset and train the model. There are various strategies for distributed training of ML models, which are beyond the scope of this blog post. We use distributed training operators supported by Kubeflow based on the model algorithm.
Hyperparameter tuning & neural architecture search
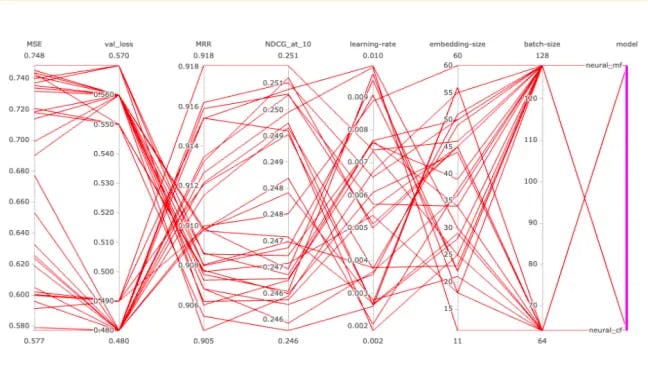
Automated tuning of machine learning models’ hyperparameters and neural architecture search is important for building models at scale. We use Katib experiments to perform hyperparameter tuning of most of the models at Unbxd. Following is an example of a personalization Katib experiment:
Model validation & deploy components
Model validation usually consists of running integration tests using the model artifacts generated in the model training step. The validation step can also serve as a model selector when multiple models are trained as part of the workflow. Once the model is validated, it is passed on to the next stage, model deployment.
Model deploy components push batch prediction output to sink databases or model serving components built using KFServing. KFServing allows us to roll out models using various APIs available for different ML platforms (TensorFlow, XGBoost, SK-learn, etc.).
Model artefacts & lineage tracking
Kubeflow Pipelines support automatic artifact and lineage tracking powered by ML Metadata. ML Pipelines usually involve various artifacts like models, data statistics, model evaluation metrics, etc.
Artifact lineage tracking helps us answer some basic questions regarding any model artifact like:
- What datasets were used to train the model?
- What were the metrics generated with this model and dataset?
And many more related questions.
AI Pipeline run metadata can also be accessed by using metadata server, pipeline run details API. This helped us build a reliable algorithm metric and run details API for various use cases.
Workflow orchestrator
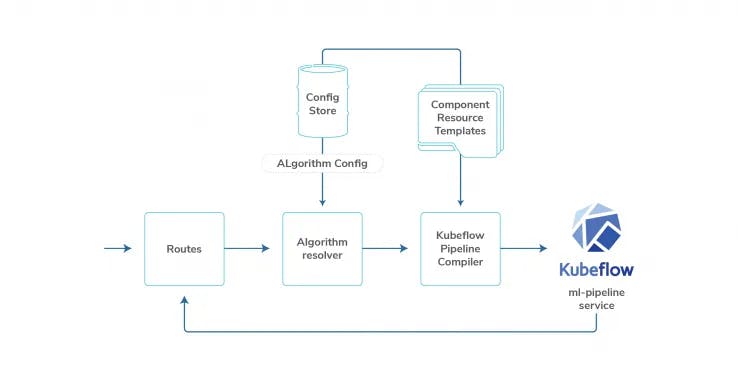
We have built an AI workflow orchestration layer responsible for generating AI workflows and resource management of each of the components in the above workflow.
Salient features include the following:
- Customer, algorithm-specific AI workflow generation
- Resource templating based on component type & its resource requirement
- Workflow status details APIs using Kubeflow MLMD APIs
- Tier/Vertical/Customer level configurations for each algorithm*
*Here algorithm could be an ML model or simply a data transformation job for some report generation
Following is the complete AI workflow representation of a personalization model.
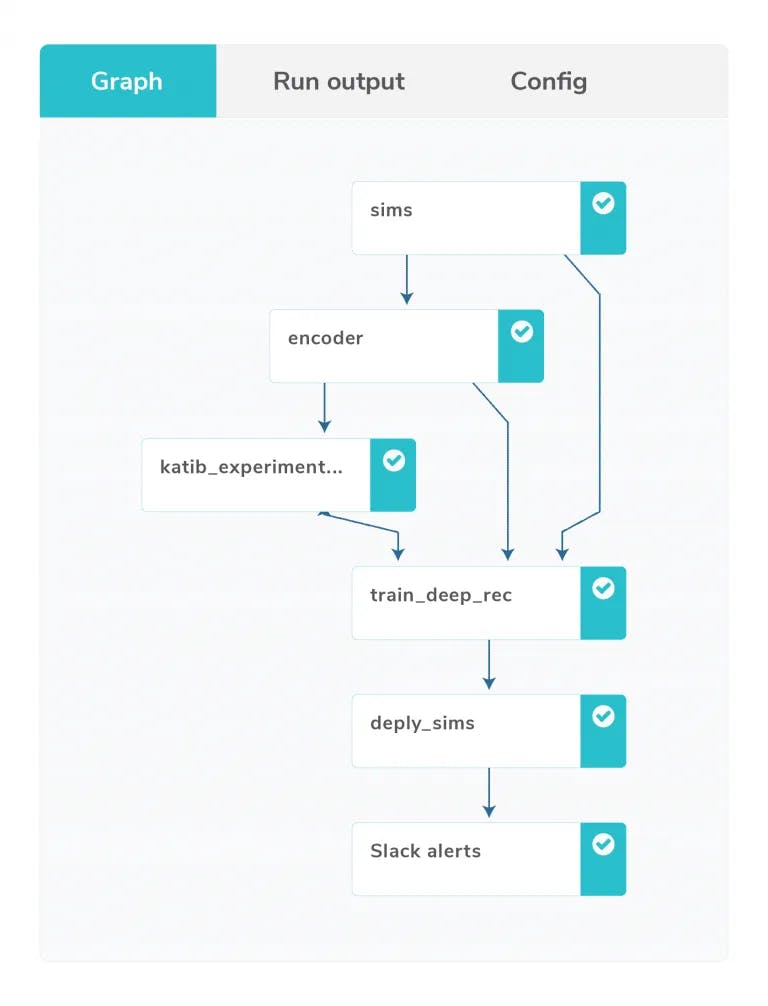
The above DAG (directed acyclic graph) demonstrates an AI workflow consisting of all the deep recommender-based personalization model stages for a customer. We host 100s of such models scheduled to run daily/weekly based on the requirement and algorithm.
Conclusion
Effectively taking models into production doesn’t have to be hard if all the stages of the ML model lifecycle are considered. As we discussed, building AI workflows for models gives us the ability to reproduce, experiment, and effectively serve models at scale. We plan to provide more details into AI Pipelines architecture & its various use cases in our next blog posts.
If you want to benefit from these AI/ML models, reach out to us.







